Sharing Our Passion for Technology
& Continuous Learning

Tales from the Trenches: A Go Optimization Example
In my last post, I talked about a change to our call pattern that allowed us to save a significant amount of money for our client, but I kind of hand-waved over the optimization work that allowed us to reduce our server cluster from >400 servers to ~10. I don't want to downplay the call-pattern, change. Without it, we wouldn't have been able to scale down our cluster nearly as much.
My team has done a significant amount of optimization work, and I'd like to cover as much of it as possible, but that's too much for one post. Today we're going to talk about the stack vs the heap, how to stay on the stack in Go, and why you would want to do that.
Stack vs Heap
Before we get into how to do this, let's talk about what we're doing and the various structures involved. We're going to talk about the stack and heap, which have related but distinct meanings from the data structures you probably learned about in college/on a wikipedia binge/wherever you happened to learn about them.
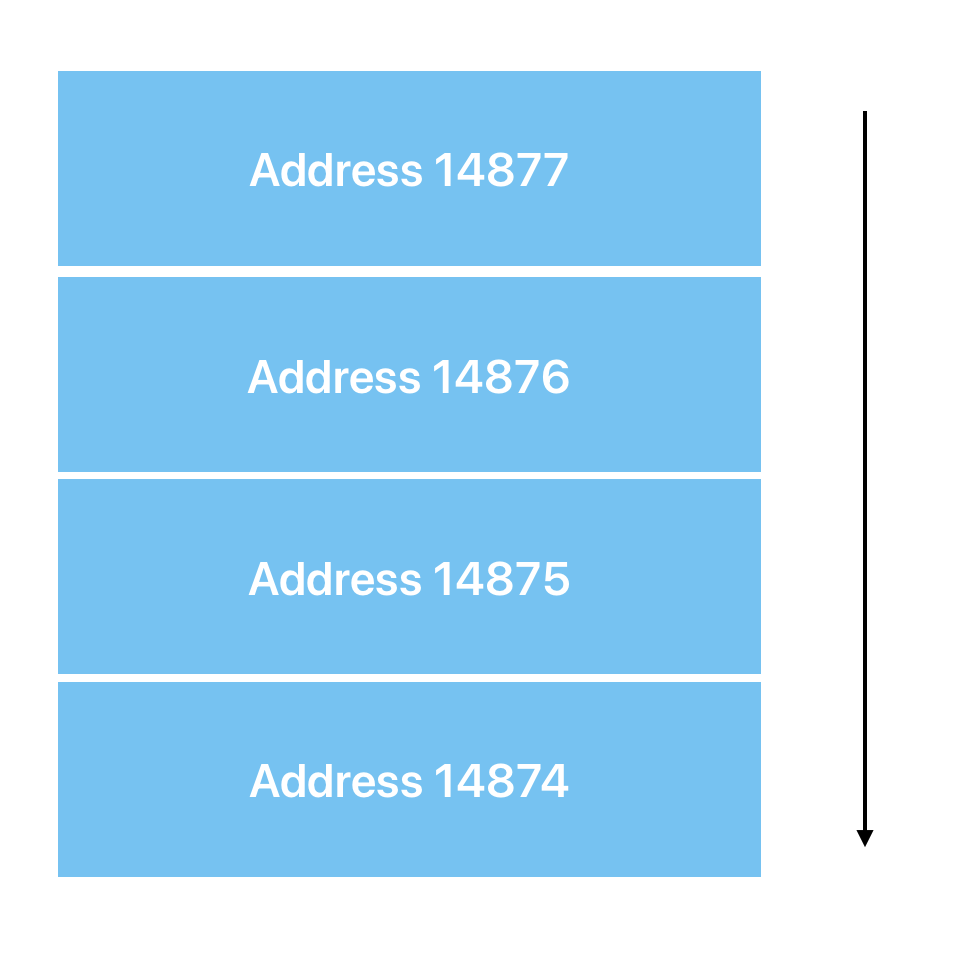
The Stack: Is a contiguous memory space. It is usually represented at the "top" of memory (highest address value) and grows downwards. It is generally added to and cleaned up for every function call. As a result, structures on the heap cannot outlive the current function scope without being copied.
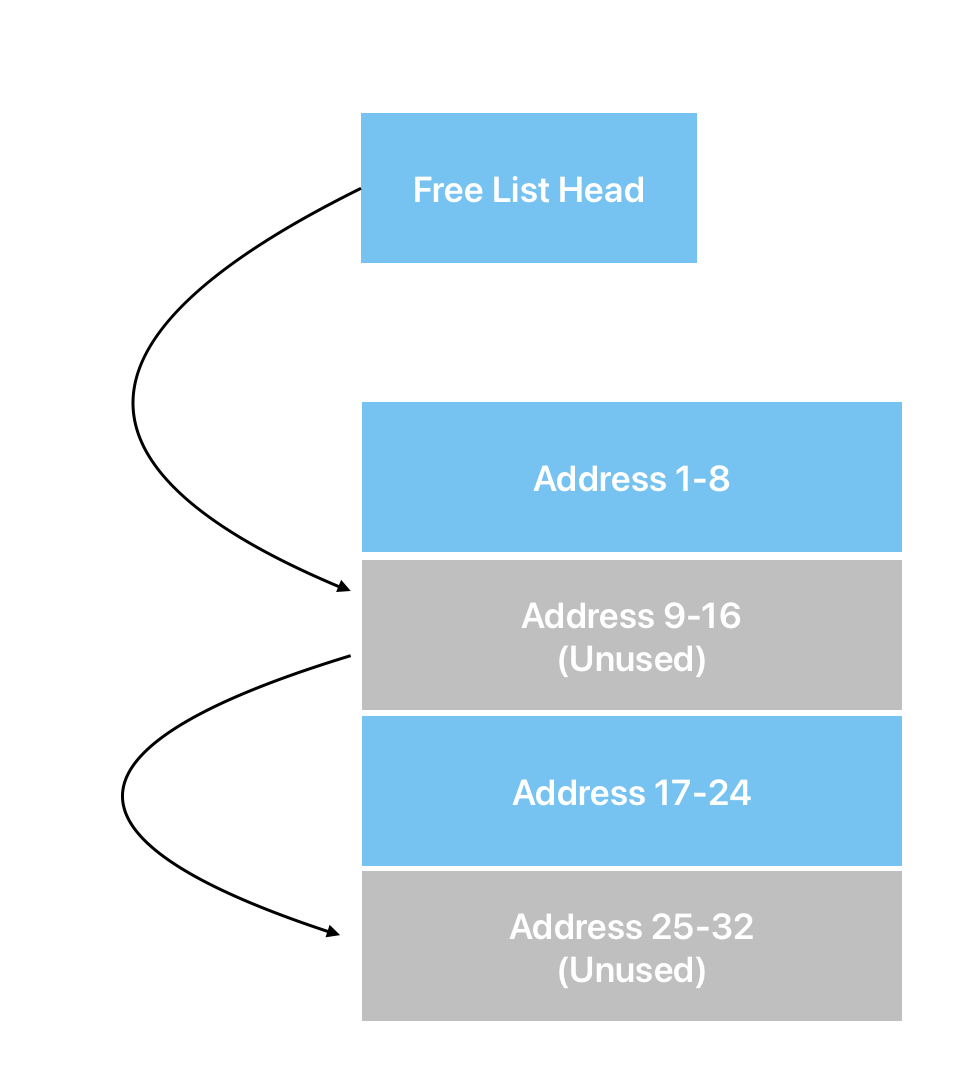
The Heap: Is a region of memory that stores long lived structures. Every time something is added to or removed from the heap, a series of lists need to be updated. On allocation, adequate space has to be found and marked as in use. On removal, the space has to be marked as free, at minimum, but in many memory management schemes adjacent memory regions will be combined to prevent fragmentation.
The trade-off here is that memory in the heap can generally be referenced from anywhere in your program safely, but is expensive to allocate. Putting something on the stack is a single mathematical instruction for both allocation and clean-up. There's a register in the computer devoted to keeping track of the stack. For small things, it's generally quicker to put them on the stack and eat the copy time, rather than putting them on the heap.
Ok, but what does all of that mean? We don't manage our own memory in Go. Well, Go's compiler performs what's called "escape analysis". If the compiler can prove that the memory is never accessed after the current function ends, it will generally leave the memory on the stack, rather than allocating heap memory for it.
Simple Example in Go
Let's start with a simple example. Imagine you have a function that adds two integers and returns a pointer to the result, like so:
func add(a, b int) *int {
result := a + b
return &result
}
In C, this would result in you reading potentially random memory, as the result variable would be cleaned up on function exit. Or, more likely, your compilation would fail unless you pass it a series of flags telling it you really know what you're doing.
Go examines this function and determines that, because you're returning the address of result, that result will be accessible after the function returns. It then helpfully puts result on the heap, and Bob's your uncle, everything ends up working. If you don't want all that overhead of putting it on the heap, you can just do the following instead:
func add(a, b int) int {
result := a + b
return result
}
Go will just leave result on the stack here, and copy the value out. Because pointers to ints are generally the same size as ints in go, we've lost very little here.
Complicated Example in Go
Now for a bit of a harder one. I ran into this on a project that I am working on. We were playing with the fancy new iterators back when Go 1.23 came out. Before we get into it, you should know that lambdas capture by reference (they see changes to the things they capture). I wrote code kind of like this:
someValue := 5
for el := range Iterator(y, z) {
doSomething(el, someValue)
}
Iterator was a function that took a few values it needed to initialize the iterator and then returned it.
Pop quiz: What goes on the heap here? I'll give you a second.
...
Answer: There's no way to know without looking at the definition of Iterator.
You see, Iterator had a definition roughly like the following:
func Iterator(y Foo, z Bar) iter.Seq[Baz] {
numIterations := doSomeStuffWithY(y)
current := Baz{}
return func(yield func(Baz) bool) {
for range numIterations {
current.Quux = computeNextValue(z, current.Quux)
if !yield(current) {
return
}
}
}
}
Can you see it? One of them is more obvious here. current is referenced by the function we return, so it has to end up on the heap. We can fix that just by moving current inside the function but, there's actually two places. I didn't see the second one for a couple cycles of trying to figure out why performance dropped off a cliff.
So there's one more you should know, Go turns your loop body into that yield function when you range over a function. Let's get rid of the sugar and see what's actually running.
someValue := 5
func (y Foo, z Bar)
numIterations := doSomeStuffWithY(y)
current := Baz{}
return func(yield func(Baz) bool) {
for range numIterations {
current.Quux = computeNextValue(z, current.Quux)
if !yield(current) {
return
}
}
}
}(y, z)(func(el Baz) bool {
doSomething(el, someValue)
return true
})
Oh, that's... not pleasant. I'm suddenly much more appreciative of what the compiler does for me. But it's much more obvious what's happening here now. someValue is actually captured by the function that my for loop was turned into.
The way we got around this was by writing an Iterator struct instead, which just manipulated the values in the struct on each cycle. It looked, roughly, like the following.
func InitIterator(y Foo, z Bar) Iterator {
return Iterator{
numIterations: doSomeStuffWithY(y),
current: Baz{},
z: z,
}
}
And then it had a Next method on it that looked something like this:
func (iter *Iterator) Next() (Baz, bool) {
if iter.numIterations <= 0 {
return Baz{}, false
}
iter.numIterations--
iter.current.Quux = computeNextValue(z, iter.current.Quux)
return iter.current, true
}
Notice the pointer receiver here, it mutates iter every time it's called. The usage looks something like this:
iter := InitIterator(y, z)
for el, ok := iter.Next(); ok; el, ok = iter.Next() {
doSomething(el, someValue)
}
Not quite as pretty as the initial version, but keeps everything off the stack.
Reducing Allocations
I don't want you walking away thinking that the heap is evil. It's quite useful. It's what lets you pass around slices without needing to know at compile time how big they are. Often there's a way to reduce heap allocations, even if you don't eliminate them. A similar thing happened to my team where we were storing pointers to float64s in a slice.
Our code looked something like this:
func MakeBigSlice(foo Foo) []*float64 {
result := make([]*float64, 1024 * 1024)
for i := range result {
el, ok := foo.CalcValue(i)
if ok {
result[i] = el
}
}
return result
}
This code, potentially, allocates millions of spots on the heap. One big one for the slice that holds all the pointers, and then a ton of little ones for each float64 that we're storing pointers to in the slice.
We were lucky, float64s have a nice invalid value called NaN, and we were able to get a serious performance improvement by switching to something like the following:
func MakeBigSlice(foo Foo) []float64 {
result := make([]float64, 1024 * 1024)
for i := range result {
el, ok := foo.CalcValue(i)
if ok {
result[i] = el
} else {
result[i] = math.NaN()
}
}
return result
}
This only allocates a single region of memory on the heap and then stores all of the float64s in it. And on top of all that, because float64s and *float64 are the same size on the machines we deploy to, we were able to save a significant amount of space as well.
Alright, that's enough for today. Time for both of us to stop procrastinating and get back to work. Make sure to come back for the next installment of Tales from the Trenches, and if you'd like to try your hand at solving some of the more subtle problems that come with operating at scale, drop one of our recruiters a line.



